
Structure de l'ADN
(Extrait de la documentation d'Anagène 2006)
Universalité de l’information génétique
Structure de l'ADN
|
|
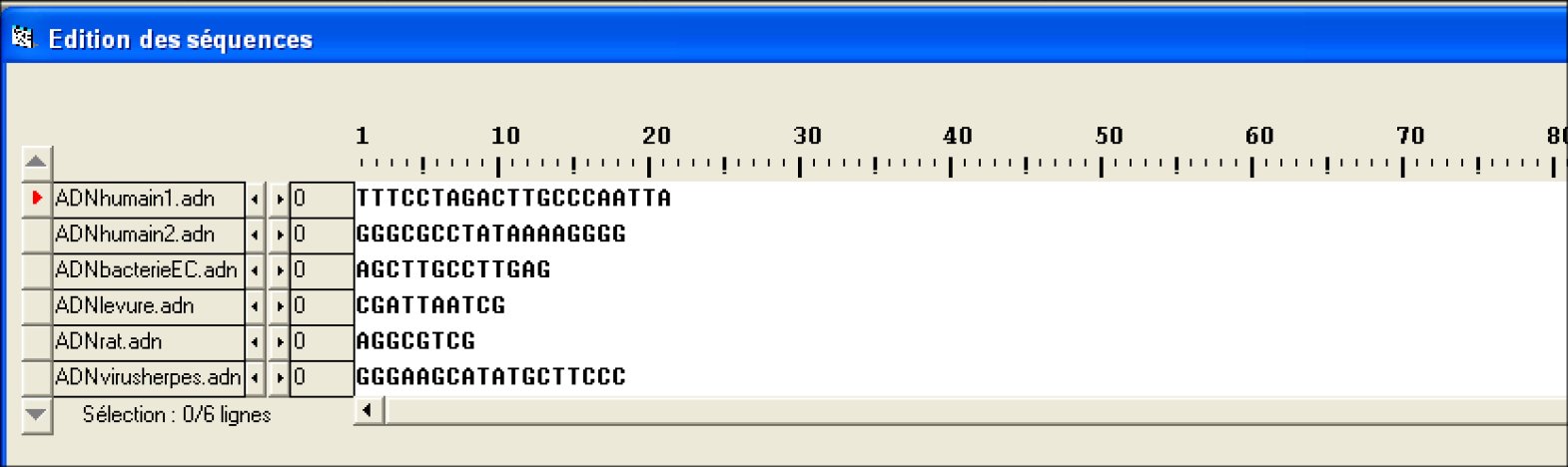
Le fichier adn.edi contient six séquences nucléiques différentes, courtes, provenant de divers êtres vivants : le Rat (ADNrat), l’Homme (ADNhumain1 et ADNhumain2), la Levure (ADNLevure), la bactérie Escherichia Coli (ADNbacterieEC), le virus de l’herpes (ADNvirusherpes). Contenu du fichier. |

Fichiers des molécules en 3D
On dispose des fragments d'ADN suivants : ADNrat.pdb, ADNhumain1.pdb et ADNhumain2.pdb, ADNLevure.pdb, ADNbacterieEC.pdb, ADNvirusherpes.pdb.
Suggestions d’utilisation pédagogique des séquences
|
|
La structure de l'ADN peut-être établie avec le logiciel RasTop. La visualisation 3D avec ce logiciel de différents fragments d’ADN d’origine très variée permet de dégager quelques caractéristiques de la molécule et l’universalité de sa structure (puisqu’on dispose de fragments d’ADN appartenant à des espèces variées. Vue élargie. |
{kind=link}
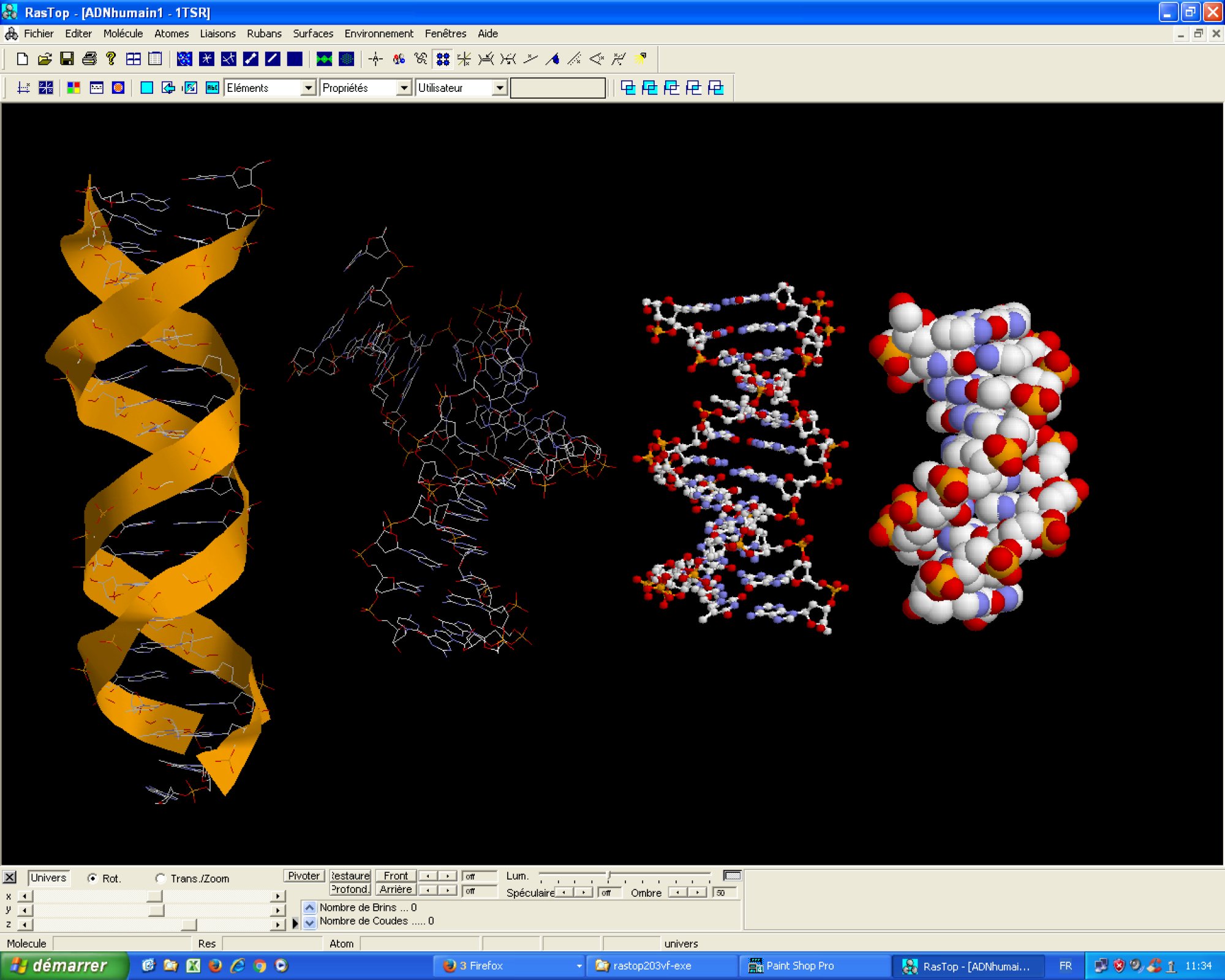{kind=link}
Il est important de préciser aux élèves qu’il ne s’agit ici que de fragments, de longueurs variées, de molécules d’ADN beaucoup plus longues en réalité.
La banque d’Anagène fournit pour chaque fragment visualisable avec RasTop, la séquence d’un des deux brins. Cela permet d’aborder avec les élèves la façon dont l’ADN est représenté dans Anagène, ce qui est essentiel pour l’utilisation ultérieure des banques de séquences.
Pour bien faire saisir en quoi la représentation d’un seul brin d’ADN est suffisante, on peut demander aux élèves de schématiser le fragment d’ADN complet à partir de la séquence fournie par Anagène. Bien entendu, puisque l’expression des gènes n’est pas au programme et que les fragments fournis dans RasTop ne sont peut-être pas codants, on ne peut pas parler de brin transcrit et non transcrit en seconde.
Ces fragments d’ADN ne sont pas homologues. On peut rechercher ce qu’ils ont en commun et en quoi ils diffèrent. Une comparaison simple permet de discuter de ce qui peut être le support de l’information génétique : proportion des différents nucléotides et ordre de leur agencement (ce qu’on appelle la séquence). Classiquement, on ne retient que le second point, mais à ce stade les deux hypothèses peuvent être retenues.
La comparaison simple de deux fragments de même longueur (ADN-humain2 et ADN-virusHerpes puisés dans le fichier adn.edi), dont la composition en bases n’est pas très éloignée, aboutit à une similitude de 22,8%. Cela est proche de la valeur que l’on s’attend à trouver si deux molécules sont composées au hasard et n’ont aucune relation de parenté. Cette remarque est importante pour bien faire saisir ultérieurement, au niveau moléculaire, les notions d’allèle et de gènes homologues (similitude très nettement supérieure à 25%).